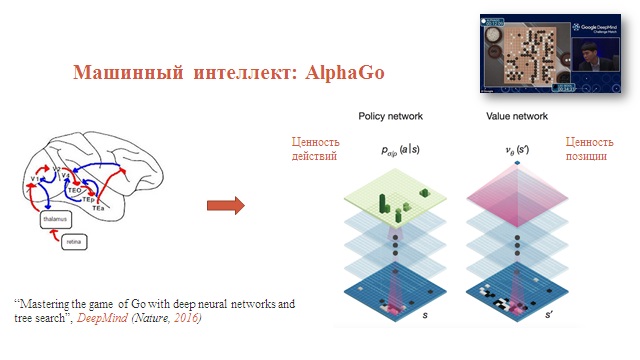
Революция в искусственном интеллекте
22 февраля 2018 года, в доме Дружбы состоялся очередной семинар организованный НТО "Кахак". С докладом "Революция в искусственном интеллекте" выступил кандидат технических наук, Александр Пак.

Ежедневно создается огромное количество новой информации и данных с помощью экономических, академических и социальных мероприятий, имеющих значительную потенциальную экономическую и социальную значимость. Например, глобальное научное сообщество ежегодно генерирует более 1,5 миллиона научных статей, очевидно, что человек не способен обрабатывать такой большой объем данных (BigData). Проблема преобразования накопленных данных в знания является нетривиальной задачей. Исторически сложилось так, что формулировка задачи для гипертекстовых документов была сформулирована в Семантической паутине в 1998 году Тимом Бернерс-Ли, когда текст (содержимое сайта) переводится вручную в набор троек (объект, объект, связь). По ряду причин реализация в то время была невозможна. Напротив, на сегодняшний день значительный прорыв в области углубленного обучения, а именно разработка сверточных и рекурсивных нейронных сетевых архитектур (LSTM, GRU, DCNN и др.) Похож на перспективный инструмент для обработки больших текстовых данных. Однако предлагаемые архитектуры при моделировании грамматики зависимости выявили ряд серьезных недостатков:
- вычислительная сложность обучения составляет более 3 градусов в зависимости от размера ввода;
- проблемы взрыва или исчезновения градиентов;
- зависимость от конкретной предметной области.
Действительно, симуляция синтаксиса для многомерного семантического пространства, где плотность распределения событий подчиняется степенному закону Ципфа, требует дополнительных механизмов:
- выравнивание статистики редких событий;
- регуляризация градиентов;
- улучшение сходимости.
Возможными решениями проблемы сходимости являются:
- свертка семантического пространства слов в классах семантической эквивалентности;
- внедрение модульной архитектуры нейронной сети;
- дополняя механизмы внимания и внутреннее состояние сети семантическим словом класса, что, естественно, поможет устранить омонимию.
Многие работы были посвящены построению текста для знания вычислительных систем. Все такие проекты объединены направлением Глубокого обучения и технологий: База знаний (база знаний) и Обработка естественного языка (обработка естественного языка). База знаний – это хранилище информации, где оно хранится не отдельно, а в контексте других блоков данных. И при извлечении данных из естественного языка – машины, которая сравнивает существительные с их сущностью, предложения – утверждения. Такое преобразование возможно не для какой-либо предметной области, а только там, где тексты подчиняются логическому дискурсу и действуют с фактами (например, юриспруденция, фармацевтика и другие точные науки).